I was looking at a media player on my phone the other day and was watching the waveform of the music shown on screen. This was a simple indication of the progress through the track and appeared to show quiet and loud sections of the track I was listening to. This got me thinking about how to extract this information as the media player I was watching must do this in real time in order to actually play the data, not just render this representation of the music.
After a bit of research into the MP3 file format I found that the file format is complex, but straight forward enough to process, so I decided to try and extract the data using PHP. I have seen a few techniques to extract the data from MP3 using PHP, but these largely involve applications like ffmpeg to convert the audio format into something like a WAV file, which is then processed.
As this is PHP there is no way (yet?!) of actually playing the sounds, so this will just be a way of extracting the audio as a stream of data and trying to represent this as an image. Also, there is quite a lot of complexity surrounding the MP3 format so whilst this post will look at extracting some of the information in the file format I would advise doing your own research into MP3 to better understand it.
The MP3 format is not free or open source, it is a commercially controlled format and so you won't find many free and open source MP3 decoders out there. I'm sure this is the reason why I can find just enough information about the format to help, but not enough to actually figure out what is going on. If you want full access to the official standard then you'll need to pay some money for the audio compression ISO standard documents.
The MP3 File Format
An MP3 file is a binary file format, meaning that you can't just throw an MP3 file into a normal text editor and expect to view the content. The structure of the typical MP3 file is a header section that may contain some metadata, followed by the audio data for the track, the two being separated by a section of 0 bit data. The header is used to store things like track name, album name, artist name, what number track this is, how long the track is, and some other information. To help with the confusion there are a couple of different formats of MP3, and those formats differ in the format of the tags and how the audio information is stored. The overall structure of the file, however, is the same.
The MP3 file can be drawn like this, with the header and audio data separated by a section of 0 bit data.
--------------------
| Header |
--------------------
0000000000000000000000000000000
--------------------
| Audio data |
--------------------
Here is a real world example of the structure of an MP3 file using a hex editor.
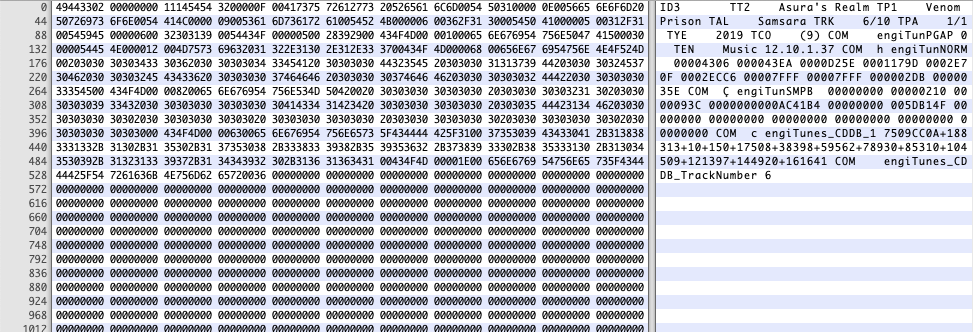
The audio data in a MP3 file is stored in a section of frames, with each frame having a header describing things like how long the frame is, the bit rate, how many samples are present etc. After the header section is the actual audio data of that frame.
The Wikipedia page on MP3 has quite a lot of detail on the structure of an MP3 file so I would read that if you want to know more, and is a good starting point.
With the structure in mind we need to open the file using PHP. By default, PHP will open a file and attempt to translate the data into some form of readable format. This makes sense in a lot of instances where a text file can just be read by PHP into memory and used. To open a binary file like and MP3 file in PHP we need to use the fopen() function with the file mode 'b' (meaning binary). For example,
$file = '04 One.mp3';
$fileHandle = fopen($file, 'rb');
We are now ready to extract the data we need fro the file.
Extracting Header Data
As an aside I thought it might be interesting to view the header information of the MP3 file.
To see if header information exists you just need to read the first 3 bytes of data from the file and if this reads "ID3" then we know that there are header tags available in the file. The ID3 standard can be pretty complex to understand and has a number of different versions available. To detect the version of ID3 in use on the file you read the next two bytes after the ID3 bit.
In PHP we can read the ID3 version by opening the file and reading the first few bytes of data from the file.
// Read file into memory.
$fileHandle = fopen('02 Impulse Crush.mp3', 'rb');
$binary = fread($fileHandle, 5);
// Detect presence of ID3 information.
if (substr($binary, 0, 3) == "ID3") {
// ID3 tags detected.
$tags['FileName'] = $file;
$tags['TAG'] = substr($binary, 0, 3);
$tags['Version'] = hexdec(bin2hex(substr($binary, 3, 1))) . "." . hexdec(bin2hex(substr($binary, 4, 1)));
}
The tags array now contains the following data.
Array
(
[FileName] => 02 Impulse Crush.mp3
[TAG] => ID3
[Version] => 4.0
)
The next few bytes of the header contain information on what version of the ID3 header is in use, a byte that sets certain flags and 4 bytes that show how long the tag is in length as a 32 bit syncsafe integer. Here is a synopsis of the first 10 bytes in the header.
3 bytes for the characters 'I', 'D' and '3'.
1 byte for the version number (2, 3 or 4)
1 byte for the revision number
1 byte setting a number of flags
- bit 5 is an experimental tag
- bit 6 sets an extended header
- bit 7 sets an unsynchronisation
4 bytes set the length of the tag itself. This is stored as a syncsafe integer.
A syncsafe integer (or synchronisation safe integer) is a way of storing an integer value in a way that means it won't interfere with the normal operation of the processing of the file itself. This is so that players that can't read ID3 headers can still process the rest of the file without any problems. The audio frame header (see later) can't be found in the header section of the ID3 header.
This essentially means that you need to ignore the most significant bit of each byte and bit shift each byte over to the right.
Synchsafe number : 00000000 00001110 00011101 01011010
real number : 00000000 00000011 10001110 11011010
To find out the full length of the header we can encapsulate this in a function where we extract the length bytes and extract them into integer values. We then add to that the header and footer values (if the footer flag has been set) before returning.
function headerOffset($fileHandle) {
// Extract the first 10 bytes of the file and set the handle back to 0.
fseek($fileHandle, 0);
$block = fread($fileHandle, 10);
fseek($fileHandle, 0);
$offset = 0;
if (substr($block, 0, 3) == "ID3") {
// We can ignore bytes 3 and 4 so they aren't extracted here.
// Extract ID3 flags.
$id3v2Flags = ord($block[5]);
$flagUnsynchronisation = $id3v2Flags & 0x80 ? 1 : 0;
$flagExtendedHeader = $id3v2Flags & 0x40 ? 1 : 0;
$flagExperimental = $id3v2Flags & 0x20 ? 1 : 0;
$flagFooterPresent = $id3v2Flags & 0x10 ? 1 : 0;
// Extract the length bytes.
$length0 = ord($block[6]);
$length1 = ord($block[7]);
$length2 = ord($block[8]);
$length3 = ord($block[9]);
// Check to make sure this is a safesynch integer by looking at the starting bit.
if ((($length0 & 0x80) == 0) && (($length1 & 0x80) == 0) && (($length2 & 0x80) == 0) && (($length3 & 0x80) == 0)) {
// Extract the tag size.
$tagSize = $length0 << 21 | $length1 << 14 | $length2 << 7 | $length3;
// Find out the length of other elements based on header size and footer flag.
$headerSize = 10;
$footerSize = $flagFooterPresent ? 10 : 0;
// Add this all together.
$offset = $headerSize + $tagSize + $footerSize;
}
}
return $offset;
}
This means that if we want to skip the header we can just call this function and fast forward through the file the number of bytes that this function returns.
There are a couple of different versions of ID3 tag available, but they can be read looking in the data for the tag names in the header and reading that tag's content. For example the ID3 version 2.0 tag "TRK" is used to store information about the name of the track, reading the next 3 bytes gives us the length of the data in that tag so all we need to do is read that many bytes into memory and decode the tag contents.
In the following example we detect the TRK tag and see that the data is 23 bytes long (17 in hexadecimal), so reading those 27 bytes as ASCII character encoding gives us the name of the track.
T R K
54 54 32
00 00 17 = 23 bytes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
00 42 72 69 6E 67 20 42 61 63 6B 20 74 68 65 20 50 6C 61 67 75 65 00
B r i n g B a c k T h e P l a g u e
In PHP, I have found that the following produces some decent results. This has a predefined list of tags and goes through each of the potential tags in the list and extracts them to an array. The code just extracts the tag, the data length and then loops through the data found to print it out in a readable manner.
$id3v22 = ["TT2", "TAL", "TP1", "TRK", "TYE", "TLE", "ULT"];
for ($i = 0; $i < count($id3v22); $i++) {
// Look for each tag within the data of the file.
if (strpos($binary, $id3v22[$i] . chr(0)) != FALSE) {
// Extract the tag position and length of data.
$pos = strpos($binary, $id3v22[$i] . chr(0));
$len = hexdec(bin2hex(substr($binary, ($pos + 3), 3)));
$data = substr($binary, ($pos + 6), $len);
$tag = substr($binary, $pos, 3);
// Extract data.
$tagData = '';
for ($a = 0; $a <= strlen($data); $a++) {
$char = substr($data, $a, 1);
if (ord($char) != 0 && ord($char) != 3 && ord($char) != 225 && ctype_print($char)) {
$tagData .= $char;
}
elseif (ord($char) == 225 || ord($char) == 13) {
$tagData .= "\n";
}
}
if ($tag == "TT2") {
$tags['Title'] = $tagData;
}
if ($tag == "TAL") {
$tags['Album'] = $tagData;
}
if ($tag == "TP1") {
$tags['Author'] = $tagData;
}
if ($tag == "TRK") {
$tags['Track'] = $tagData;
}
if ($tag == "TYE") {
$tags['Year'] = $tagData;
}
if ($tag == "TLE") {
$tags['Length'] = $tagData;
}
if ($tag == "ULT") {
$tags['Lyric'] = $tagData;
}
}
}
The ID3 version 3 and 4 tags are very similar, they just consist of 4 character code and so need the appropriate offsets to extract the data.
$id3v23 = ["TIT2", "TALB", "TPE1", "TRCK", "TYER", "TLEN", "USLT"];
// Look for each tag within the data of the file.
for ($i = 0; $i < count($id3v23); $i++) {
if (strpos($binary, $id3v23[$i] . chr(0)) != FALSE) {
// Extract the tag position and length of data.
$pos = strpos($binary, $id3v23[$i] . chr(0));
$len = hexdec(bin2hex(substr($binary, ($pos + 5), 3)));
$data = substr($binary, ($pos + 10), $len);
$tag = substr($binary, $pos, 4);
// Extract tag and data.
$tagData = '';
for ($a = 0; $a <= strlen($data); $a++) {
$char = substr($data, $a, 1);
if (ord($char) != 0 && ord($char) != 3 && ord($char) != 225 && ctype_print($char)) {
$tagData .= $char;
}
elseif (ord($char) == 225 || ord($char) == 13) {
$tagData .= "\n";
}
}
if ($tag == "TIT2") {
$tags['Title'] = $tagData;
}
// the rest of the tags would be extracted here into the tags array.
}
}
One thing to note from these examples is that there are other tags available in ID3, but this just looks at some of the more common ones.
Here are some results of looking at a random selection of MP3 files from my collection.
Array
(
[FileName] => 07 Bring Back the Plague.mp3
[TAG] => ID3
[Version] => 2.0
[Title] => Bring Back the Plague
[Album] => Death Atlas
[Author] => Cattle Decapitation
[Track] => 7/15
[Year] => 2019
)
Array
(
[FileName] => 11 All That Has Gone Before.mp3
[TAG] => ID3
[Version] => 2.0
[Title] => All That Has Gone Before
[Album] => Grievances
[Author] => Rolo Tomassi
[Track] => 11/11
[Year] => 2015
)
Array
(
[FileName] => 02 Impulse Crush.mp3
[TAG] => ID3
[Version] => 4.0
[Title] => Impulse Crush
[Album] => The Language of Injury
[Author] => ITHACA
[Track] => 2
)
Array
(
[FileName] => 06 Asura's Realm.mp3
[TAG] => ID3
[Version] => 2.0
[Title] => Asura's Realm
[Album] => Samsara
[Author] => Venom Prison
[Track] => 6/10
[Year] => 2019
)
If you want a full dive into ID3 then you can take a look at the ID3 website that contains lots of information about the standard including all of the tags and other information that I have skipped over here.
Extracting Audio Data
The body of the audio data contains a a series of frames that each represent a fraction of a second of audio data. The audio data has a 32bit header section split into 13 different parts followed by the audio data itself. Each frame starts with a series of synchronisation bits 12 bits in length, which means all we need to do to read the data is skip past the header information and then find every instance of 12 bits in a row. The header takes the following format.
1-12: First 12 bits all containing 1 MP3 sync word.
13: The version.
14-15: The layer.
16: Error protection.
17-20: The bitrate.
21-22: The sampling rate.
23: Padding bit (0 means the frame is not padded).
24: Private bit.
25-26: The mode.
27-28: The mode extension.
29: Copy-right flag (0 means not copy-righted).
30: Original (0 means copy of original media).
31-32: Emphasis.
After the header comes the actual audio data, which will be a length of bytes calculated by looking at the bit rate and the sample rate. Using a hex editor to inspect the file we can see a header starting with FFB, followed by the bytes for the header flags and the actual audio data itself.

Quite a few of the header components work on a lookup table basis. Meaning that a value of 0 in the versions bit translates to version 2.5 in the lookup table. The lookup values needed for this lookup process are as follows, this is encapsulated into a class along with the above headerOffset() method to tie everything together.
class Mp3 {
protected $versions = [
0x0 => '2.5',
0x1 => 'x',
0x2 => '2',
0x3 => '1',
];
protected $layers = [
0x0 => 'x',
0x1 => '3',
0x2 => '2',
0x3 => '1',
];
protected $bitrates = [
'V1L1' => [0,32,64,96,128,160,192,224,256,288,320,352,384,416,448],
'V1L2' => [0,32,48,56, 64, 80, 96,112,128,160,192,224,256,320,384],
'V1L3' => [0,32,40,48, 56, 64, 80, 96,112,128,160,192,224,256,320],
'V2L1' => [0,32,48,56, 64, 80, 96,112,128,144,160,176,192,224,256],
'V2L2' => [0, 8,16,24, 32, 40, 48, 56, 64, 80, 96,112,128,144,160],
'V2L3' => [0, 8,16,24, 32, 40, 48, 56, 64, 80, 96,112,128,144,160],
];
protected $samplerates = [
'1' => [44100, 48000, 32000],
'2' => [22050, 24000, 16000],
'2.5' => [11025, 12000, 8000],
];
protected $samples = [
1 => [1 => 384, 2 =>1152, 3 => 1152,],
2 => [1 => 384, 2 =>1152, 3 => 576,],
];
// Other methods.
}
With these lookup tables in place we can extract the data in the MP3 file. I have added lots of comments here to show what is going on, but we are essentially pulling out the heading data, finding out how long the frame data is and the reading that data into memory.
public function readAudioData() {
// Open the file.
$fileHandle = fopen($this->file, "rb");
// Skip header.
$offset = $this->headerOffset($fileHandle);
fseek($fileHandle, $offset, SEEK_SET);
while (!feof($fileHandle)) {
// We nibble away at the file, 10 bytes at a time.
$block = fread($fileHandle, 8);
if (strlen($block) < 8) {
break;
}
//looking for 1111 1111 111 (frame synchronization bits)
else if ($block[0] == "\xff" && (ord($block[1]) & 0xe0)) {
$fourbytes = substr($block, 0, 4);
// The first block of bytes will always be 0xff in the framesync
// so we ignore $fourbytes[0] but need to process $fourbytes[1] for
// the version information.
$b1 = ord($fourbytes[1]);
$b2 = ord($fourbytes[2]);
$b3 = ord($fourbytes[3]);
// Extract the version and create a simple version for lookup.
$version = $this->versions[($b1 & 0x18) >> 3];
$simpleVersion = ($version == '2.5' ? 2 : $version);
// Extract layer.
$layer = $this->layers[($b1 & 0x06) >> 1];
// Extract protection bit.
$protectionBit = ($b1 & 0x01);
// Extract bitrate.
$bitrateKey = sprintf('V%dL%d', $simpleVersion, $layer);
$bitrateId = ($b2 & 0xf0) >> 4;
$bitrate = isset($this->bitrates[$bitrateKey][$bitrateId]) ? $this->bitrates[$bitrateKey][$bitrateId] : 0;
// Extract the sample rate.
$sampleRateId = ($b2 & 0x0c) >> 2;
$sampleRate = isset($this->samplerates[$version][$sampleRateId]) ? $this->samplerates[$version][$sampleRateId] : 0;
// Extract padding bit.
$paddingBit = ($b2 & 0x02) >> 1;
// Extract framesize.
if ($layer == 1) {
$framesize = intval(((12 * $bitrate * 1000 / $sampleRate) + $paddingBit) * 4);
}
else {
// Later 2 and 3.
$framesize = intval(((144 * $bitrate * 1000) / $sampleRate) + $paddingBit);
}
// Extract samples.
$frameSamples = $this->samples[$simpleVersion][$layer];
// Extract other bits.
$channelModeBits = ($b3 & 0xc0) >> 6;
$modeExtensionBits = ($b3 & 0x30) >> 4;
$copyrightBit = ($b3 & 0x08) >> 3;
$originalBit = ($b3 & 0x04) >> 2;
$emphasis = ($b3 & 0x03);
// Calculate the duration and add this to the running total.
$this->duration += ($frameSamples / $sampleRate);
// Read the frame data into memory.
$frameData = fread($fileHandle, $framesize - 8);
// do something with the frame data.
}
else if (substr($block, 0, 3) == 'TAG') {
// If this is a tag then jump over it.
fseek($fileHandle, 128 - 10, SEEK_CUR);
}
else {
fseek($fileHandle, -9, SEEK_CUR);
}
}
}
With the data in the frame now in memory we can start looking at visualising the content. I was able to find some information about what sort of content this section contained, but it's quite complex. Essentially, as it's a digital representation of the audio frequency signal there is lots of compression going on in order to convert one type of data to another.
A frame of data is actually quite long for what I am trying to do here. Rather than use all of the data in the frame itself (which might be more than 1000 bytes per frame at some higher quality levels) it seemed best to grab just parts of the data and use that.
To help with this I built a rendering function that looks at a data property in the class and renders out the image depending on what values had been added to the array. This function boxes in the data to be within the height of the image itself and is generic enough that most values added to the data array produced some form or result. The length of the image is dictated by the length of the audio file being processed (ie, how long the data array is).
public function renderAsImage() {
$height = 500;
// Create image resource.
$image = imagecreate($this->duration * $this->factor, $height);
// Set background colour to black.
imagecolorallocate($image, 0, 0, 0);
// Assign a collection of foreground colours we can use.
$colors[] = imagecolorallocate($image, 255, 255, 255);
$colors[] = imagecolorallocate($image, 255, 0, 0);
$colors[] = imagecolorallocate($image, 0, 255, 0);
$colors[] = imagecolorallocate($image, 0, 0, 255);
$colors[] = imagecolorallocate($image, 128, 0, 0);
$colors[] = imagecolorallocate($image, 0, 128, 0);
$colors[] = imagecolorallocate($image, 0, 0, 128);
// Loop through the data and draw onto the canvas.
foreach ($this->data as $index => $data) {
foreach ($data as $dataDuration => $dataBit) {
imagefilledellipse($image, $dataDuration, (($dataBit * 2) - $height) * -1, 2, 2, $colors[$index]);
}
}
// Render the image out, using the original filename as part of the image name.
imagepng($image, $this->filename . '.png');
}
To create our image of the audio output we now just need to process the audio data and then render the data out. We will be left with an image file that should look something like the audio file we inputted.
$mp3 = new Mp3('11 All That Has Gone Before.mp3');
$mp3->readAudioData();
$mp3->renderAsImage();
My first attempt was to try and average out the first 8 bytes of data and send that to the data array.
$average = 0;
$sampleBytes = 8;
for ($i = 0; $i <= $sampleBytes; $i++) {
$average += ord($frameData[$i]);
}
$this->data[0][$this->duration * $this->factor] = $average / $sampleBytes;
This produced some ok results, but the averages are quite messy. I found a 1kHz tone lasting for 30 seconds as a good test bed for seeing what this process produces. This file created a band of data that didn't look right.

After some experimentation I found that certain byte positions indicated the strength or the frequency of the signal being produced. Using these values I was able to put together a collection of 7 data points from each frame that seemed to create some better results.
$this->data[0][$this->duration * $this->factor] = ord($frameData[0]);
$this->data[1][$this->duration * $this->factor] = ord($frameData[2]);
$this->data[2][$this->duration * $this->factor] = ord($frameData[9]);
$this->data[3][$this->duration * $this->factor] = ord($frameData[16]);
$this->data[4][$this->duration * $this->factor] = ord($frameData[23]);
Here are some examples of image files generated from music I have been listening to recently. The files are 500px high and however long the song is wide.
Chopin Prelude #1 in C. A short piece that I used as a test file as it shows the structure of the audio quite nicely.
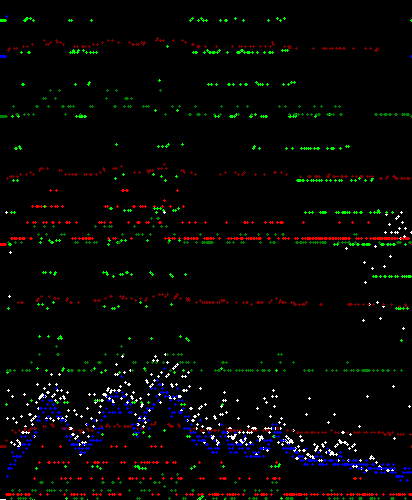
CLSR. by Ithaca is a great example of this in practice as the song starts quiet, has a loud middle part and is quiet towards the end.
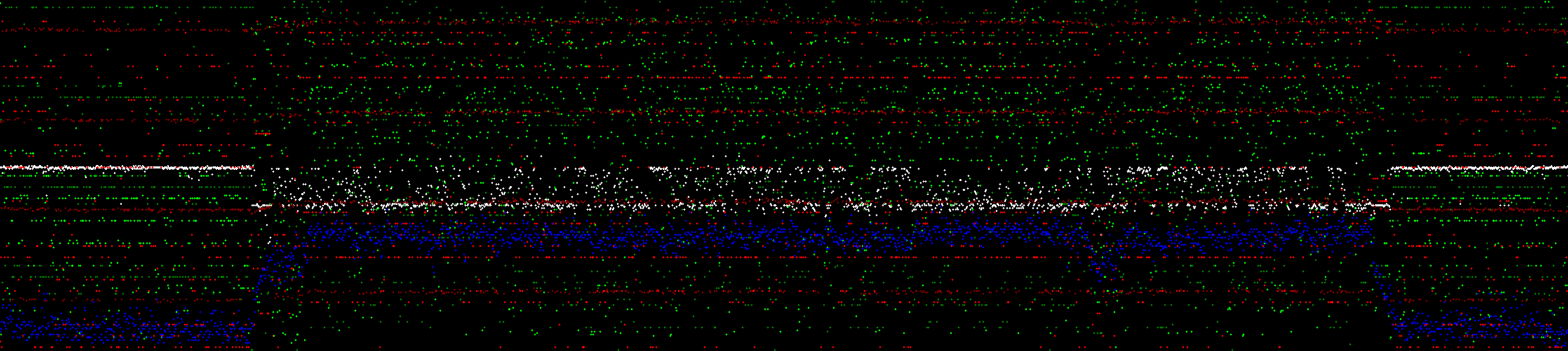
I was interested in processing Wrench, by The Almighty as it has a couple of sections of complete silence in the middle of the song. These show up really well in the graphic.

Smells Like Teen Spirit by Nirvana is also a great example of this at work as it clearly shows the "quiet-loud-quiet" structure of the song, as well as the long fadeout at the end.

Bring back the plague by Cattle Decapitation is utterly brutal, and that shows in the wide spectrum of noise being produced here.

Open Wound, the awesome recent release by Svalbard, also produces some good results. Notice the long fadeout at the end of the song.

Finally, I wanted to try One by Metallica as this has a noticeable quiet section at the start.

I could probably improve the results being produced here, but I'm happy enough with the results for now. At least I have a way of extracting the raw data from the MP3 file and a (rather course) way of representing that data.
If you want all of the code I have used here then I have created a gist that collects all this code together as a class. Feel free to adapt to your own needs. If you spot any problems or issues with it then please let me know and I'll correct it as much as I can.
I also found some good resources whilst researching this topic that helped me put together much of what is present in this post:









Comments
nice & helpful article!
i needed this in my new project.
tnx for share
Submitted by Ali Emadzadeh on Sun, 07/25/2021 - 18:35
PermalinkHi!
Thirst of all, what an awesome expirement.I haven't actually had the time to test your code, but the basics will give me what I need. So super thanks for that. (trying to build a music file to sheet music thingy... )
Second of all, I got distracted and started wandering your site, more awesome stuff! cool, love it! It's truly amazing that you take and make the time to publish your ideas, and code :) Keep up the good work and thank you very much!
Kind regards,
Jasper
Submitted by Jasper on Fri, 05/13/2022 - 09:00
PermalinkThanks very much Jasper! I really appreciate you taking the time to comment.
Good luck with your project :) Feel free to post any fixes back to me and maybe they can be a "part 2" of this post.
Submitted by philipnorton42 on Fri, 05/13/2022 - 10:25
PermalinkI am not sure where you’re getting your info, but great topic.
Submitted by neurontnS on Fri, 12/30/2022 - 13:15
PermalinkAdd new comment